Month May 2024

Want to improve the quality of your data annotations? Then check out this article. We will discuss everything about polygons, creation of polygon annotations, data accuracy, and how Infosearch BPO can help you. Infosearch BPO is a company that horizontally… Continue Reading →

Infosearch offers excellent data annotation services for machine learning and artificial intelligence. We combine human annotation services with automated tools and deliver accurate annotated datasets. Contact Infosearch for outsourcing data annotation services. The concept of artificial intelligence (AI) has shown… Continue Reading →

In the competitive marketplace of today, one of the most important activities in which businesses are involved is that of efficiency of operations, and minimization of costs with the aim of acquiring a competitive advantage over the others. Infosearch BPO… Continue Reading →

Infosearch is a BPO outsourcing company providing various BPO services, Annotation support, Data management and Call Centre services to Global businesses. Nowadays, BPO (business Process Outsourcing) has become an indispensable strategy for modern businesses; From cost savings to a lift… Continue Reading →

Infosearch is an exceptional bounding box annotation service provider for various industries for machine learning purposes. Read this article to learn more about bounding box annotations, and contact Infosearch for all your bounding box annotation and labelling services. Contour lines,… Continue Reading →
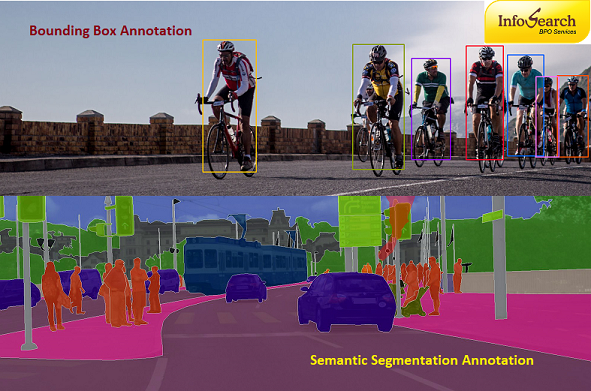
Deciding between bounding box annotation or semantic segmentation annotation is dependent on the task specificities, the level of abstraction needed and on the available resources. Infosearch provides both bounding box annotation and semantic segmentation annotation services and of course many… Continue Reading →
